In today’s digital landscape, effective document management and retrieval are crucial for productivity. With the proliferation of diverse file types—such as PDFs, Word documents, spreadsheets, and more—navigating through them can become cumbersome. Enter Langchain, a powerful framework designed to streamline the process of document loading and handling. In this article, we’ll delve into the topic of Langchain Document_Loaders Mixed File Type, exploring their features, benefits, and practical applications to enhance your workflow.
Understanding Langchain and Its Purpose
Langchain is a framework that simplifies the integration of language models with various applications. It offers a robust set of tools for developers, enabling them to process and manage text data efficiently. One of its key functionalities is the ability to load documents from a wide range of file types, allowing users to extract meaningful information regardless of the format.
Why Mixed File Types Matter
Organizations today often deal with a mix of file types—ranging from text documents to spreadsheets and presentations. Each file type may contain critical information, but managing them individually can lead to inefficiencies. By leveraging Langchain Document_Loaders Mixed File Type, users can unify their document handling processes, leading to improved access and insights.
Features of Langchain Document Loaders
1. Versatility in File Handling
Langchain’s document loaders can handle a variety of file formats, including:
- PDFs: Extract text and data from portable document formats.
- Word Documents: Access information stored in .docx files.
- Spreadsheets: Process data from Excel files and CSVs.
- Text Files: Read plain text documents without additional formatting.
This versatility allows users to create a seamless workflow that accommodates various document types without switching tools.
2. Automatic Metadata Extraction
One of the standout features of Langchain document loaders is their ability to automatically extract metadata from files. This includes details like:
- File type: Identifying the format of the document.
- Author information: Capturing the creator of the document.
- Creation and modification dates: Keeping track of when the document was made and last edited.
Having this metadata readily available can enhance document management and retrieval processes, making it easier to organize and locate files.
3. Integrated Preprocessing
Langchain document loaders come equipped with preprocessing capabilities that allow users to clean and format data before it’s used in applications. This includes:
- Text normalization: Ensuring consistency in text representation.
- Tokenization: Breaking down text into manageable pieces for analysis.
- Language detection: Identifying the language of the document for proper processing.
These preprocessing steps enhance the quality of data, making it more suitable for machine learning models and other applications.

Setting Up Langchain Document Loaders for Mixed File Types
Getting started with Langchain document loaders is straightforward. Here’s a step-by-step guide to help you set up and utilize these tools effectively:
Step 1: Install Langchain
First, ensure you have the Langchain library installed in your environment. You can do this using pip:
bash
Copy code

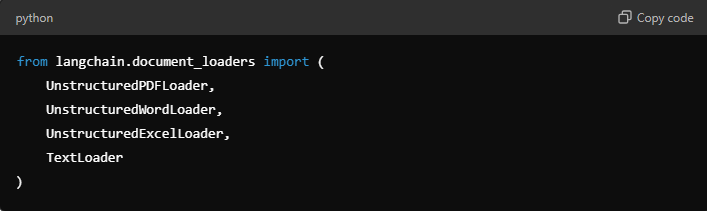
Step 2: Import Necessary Modules
After installation, import the necessary modules in your Python script or Jupyter Notebook:
python
Copy code
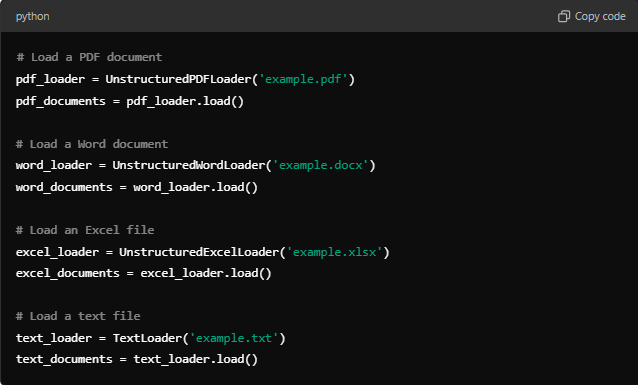
Step 3: Load Documents
You can now load documents of different types using the appropriate loaders. For example:
python
Copy code
Step 4: Combine Loaded Documents
To enhance your workflow further, you may want to combine the loaded documents into a single list for unified processing:
python
Copy code

Step 5: Process the Documents
Now that you have a unified list of documents, you can process them according to your needs—be it text analysis, data extraction, or feeding them into a machine learning model.
Practical Applications of Langchain Document Loaders
1. Research and Academic Work
For researchers and academics, the ability to load and analyze mixed file types is invaluable. Langchain allows for the aggregation of literature, reports, and data sets, facilitating comprehensive reviews and meta-analyses.
2. Business Intelligence
In a business context, organizations can leverage Langchain document loaders to analyze reports, presentations, and financial documents. This can lead to better insights and decision-making processes.
3. Content Creation
Content creators can use Langchain to gather materials from various sources—be it articles, reports, or texts—streamlining their research process and enhancing the quality of their outputs.
4. Legal Document Management
In the legal field, professionals often work with diverse document types, including contracts, briefs, and affidavits. Langchain’s capabilities can help legal teams efficiently manage and retrieve pertinent information.
Challenges and Considerations
While Langchain document loaders offer significant advantages, there are some considerations to keep in mind:
- File Compatibility: Ensure that the specific file formats you intend to work with are supported by Langchain.
- Data Quality: The effectiveness of your analysis will depend on the quality of the documents loaded. Proper preprocessing can help mitigate issues.
- Performance: Loading and processing large volumes of documents may require optimization for performance, especially in resource-constrained environments.
Conclusion
Utilizing Langchain Document_Loaders Mixed File Type can significantly enhance your workflow, making document management more efficient and effective. By leveraging the versatility and features of Langchain, users can streamline their processes, improve data quality, and gain valuable insights from diverse information sources.
Whether you’re in research, business, content creation, or legal practice, embracing this innovative approach can transform the way you handle documents. As the demand for efficient data processing continues to grow, tools like Langchain will play a pivotal role in shaping the future of information management. Embrace the potential of mixed file types today, and take your workflow to new heights!
FAQs About Langchain Document_Loaders Mixed File Type
1. What are Langchain document loaders?
Langchain document loaders are tools within the Langchain framework designed to load and manage documents from various file types, such as PDFs, Word documents, Excel spreadsheets, and plain text files.
2. What types of files can I load using Langchain?
You can load a variety of file types, including:
- PDFs
- Word documents (.docx)
- Excel files (.xlsx)
- Text files (.txt)
- CSV files
3. Do I need any special libraries to use Langchain document loaders?
You only need to install the Langchain library, which you can do via pip. It comes with built-in support for handling different document types.
4. How do I install Langchain?
You can install Langchain using pip with the following command:
bash
Copy code

5. Can I combine documents from different file types?
Yes! You can load documents from multiple file types and combine them into a single list for unified processing.
6. What preprocessing capabilities do Langchain document loaders offer?
Langchain document loaders can perform various preprocessing tasks, such as text normalization, tokenization, and language detection, to enhance data quality before further analysis.
7. What are the practical applications of using Langchain document loaders?
Langchain document loaders are beneficial in various fields, including:
- Research and academic work
- Business intelligence
- Content creation
- Legal document management


